Differentiable Optimization of Similarity Scores Between Models and Brains
Abstract
What metrics should guide the development of more realistic models of the brain? One proposal is to quantify the similarity between models and brains using methods such as linear regression, Centered Kernel Alignment (CKA), and angular Procrustes distance. To better understand the limitations of these similarity measures we analyze neural activity recorded in five experiments on nonhuman primates, and optimize synthetic datasets to become more similar to these neural recordings. How similar can these synthetic datasets be to neural activity while failing to encode task relevant variables? We find that some measures like linear regression and CKA, differ from angular Procrustes, and yield high similarity scores even when task relevant variables cannot be linearly decoded from the synthetic datasets. Synthetic datasets optimized to maximize similarity scores initially learn the first principal component of the target dataset, but angular Procrustes captures higher variance dimensions much earlier than methods like linear regression and CKA. We show in both theory and simulations how these scores change when different principal components are perturbed. And finally, we jointly optimize multiple similarity scores to find their allowed ranges, and show that a high angular Procrustes similarity, for example, implies a high CKA score, but not the converse.
Content
- Optimization of Similarity Scores
- Scores to Capture Principal Components
- High Scores Failing to Encode Task Variables
- Metric Cards
- Similarity Package
Optimization of Similarity Scores
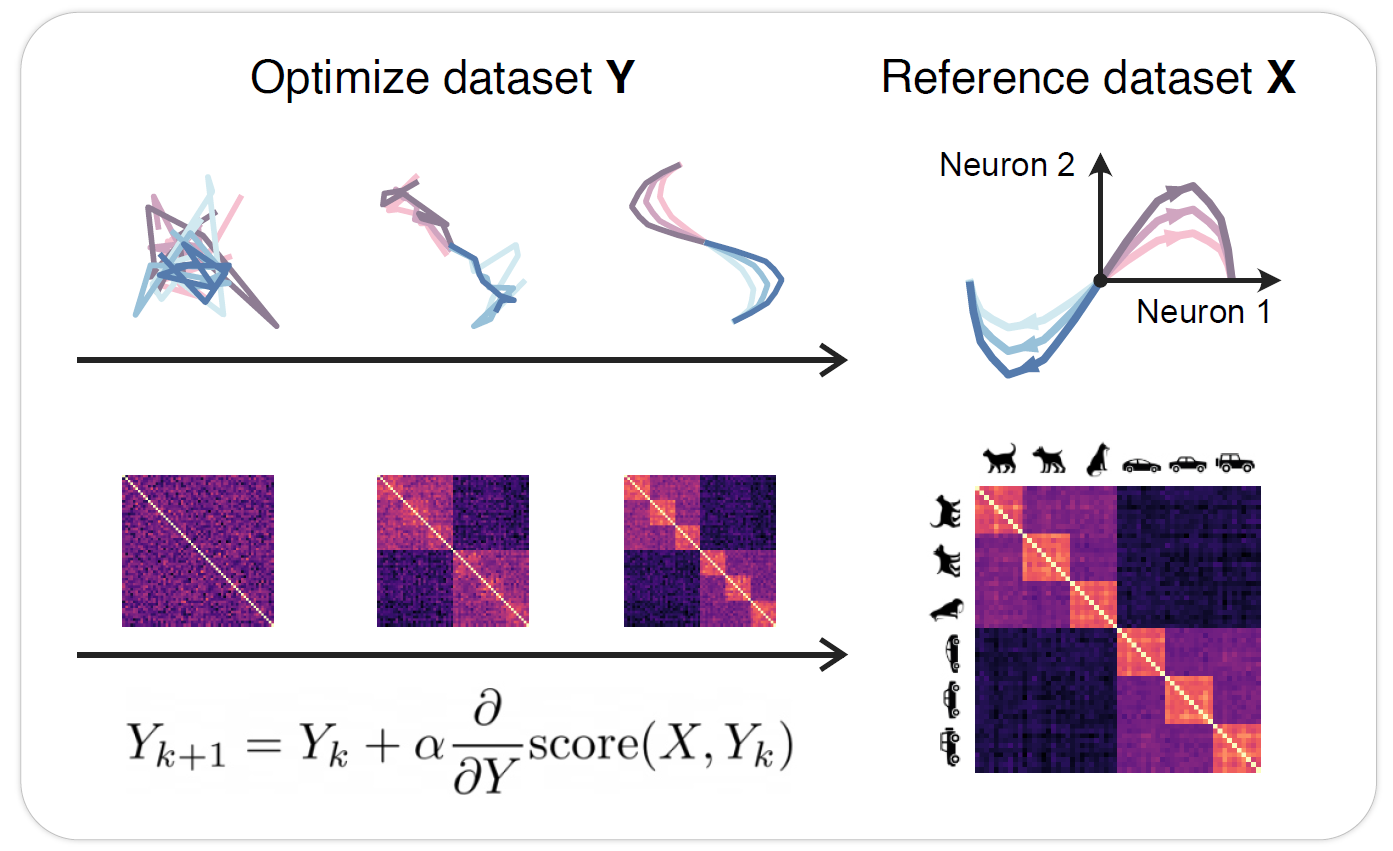
To better understand the properties of similarity measures we optimize synthetic datasets Y to become more similar to a reference dataset X, for example, neural recordings.
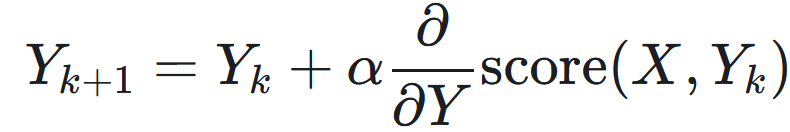
Reference
Ridge Regression

CKA

Procrustes Angular Score

Scores to Capture Principal Components
Different similarity measures differentially prioritize learning principal components of the data.
High Scores Failing to Encode Task Variables
Optimizing for similarity scores reveals model datasets with high scores that fail to encode all the relevant task variables.
Metric Cards
Invariances Properties
Invariance classes:
- PT: Permutation Transformation
- OT: Orthogonal Transformation
- ILT: Invertible Linear Transformation
- IS: Isotropic Scaling
- TR: Translation
- AT: Affine Transformation
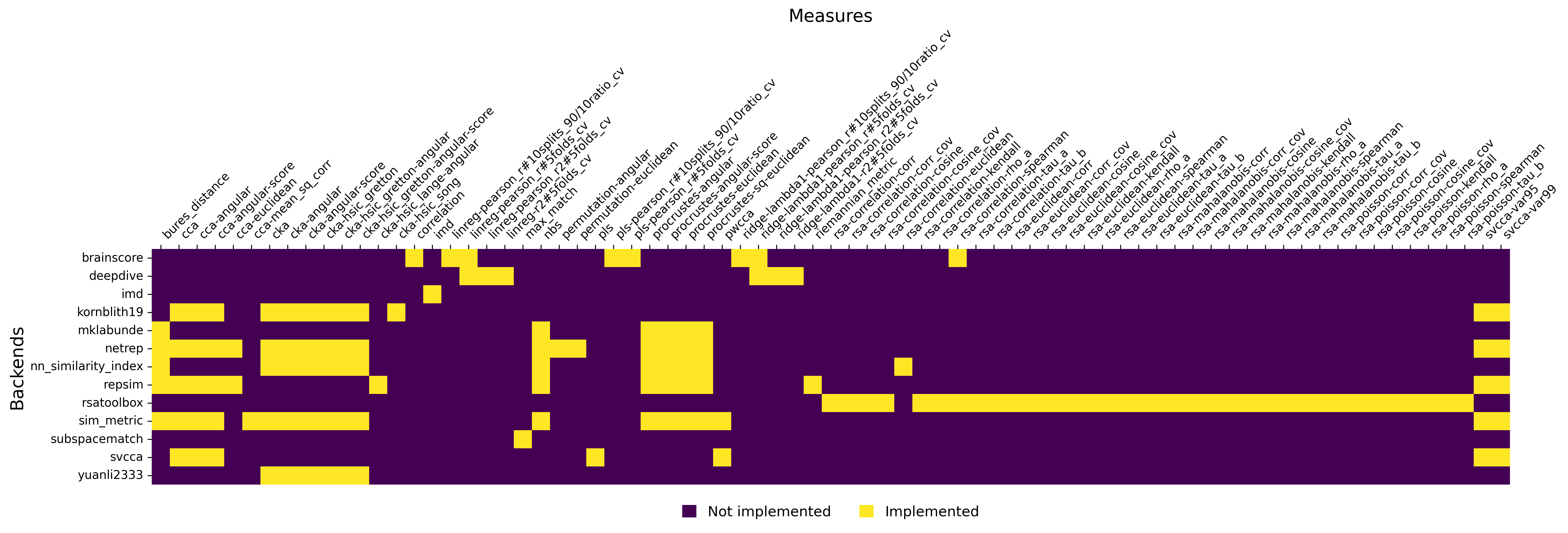
Similarity Package
We also provide a Python package that gathers existing implementations of similarity measures into a single package with a common and customizable interface.